 Penso che capiterà a tutti quanti, prima o poi, di crescere e di guardare al proprio passato con un misto di tenerezza, rimpianto e nostalgia. Ma, per fortuna le sorti, seppur né magnifiche né progressive, rendono talvolta ridicoli certi ricordi. Sto pensando, per essere meno nebulosi, a quando provai il mio primo scanner e passai ore ed ore a scansionare i miei libri e appunti, per poi trasformarli tramite un software OCR in degli ordinati file. Ma quanti errori! Non è nemmeno tanto tempo fa, ma se ci guardiamo attorno troviamo dei software OCR migliori per estrarre e copiare testi da pdf e immagini. Come ad esempio il sito che stiamo per presentare.
Penso che capiterà a tutti quanti, prima o poi, di crescere e di guardare al proprio passato con un misto di tenerezza, rimpianto e nostalgia. Ma, per fortuna le sorti, seppur né magnifiche né progressive, rendono talvolta ridicoli certi ricordi. Sto pensando, per essere meno nebulosi, a quando provai il mio primo scanner e passai ore ed ore a scansionare i miei libri e appunti, per poi trasformarli tramite un software OCR in degli ordinati file. Ma quanti errori! Non è nemmeno tanto tempo fa, ma se ci guardiamo attorno troviamo dei software OCR migliori per estrarre e copiare testi da pdf e immagini. Come ad esempio il sito che stiamo per presentare.
OCR online: come fare ad estrarre testo e immagini?
Visita il sito
Alcuni staranno guardando abbastanza basiti la sigla di tre lettere scritta sopra: cosa vorrà mai dire OCR? OCR sta per Optical Character Recognition, o per dirla nell’italica lingua: Riconoscimento Ottico dei Caratteri. Si tratta, in sostanza, di una serie di algoritmi che analizzano la forma di un’immagine e da lì calcolano le lettere che sono rappresentate. A cosa serve? Serve per estrarre il testo da un’immagine o da un documento scansionato, testo che potrà essere quindi copiato su un normale elaboratore di testi e di conseguenza modificato, elaborato, integrato, corretto, formattato e quant’altro.
Per funzionare bene l’OCR integra anche un vocabolario in grado di riconoscere le parole e nei casi migliori ricostruire un vocabolo anche se alcune lettere non sono visibili. I primi esempi di OCR non brillavano certo di precisione, ma oramai, sopratutto in campo professionale, l’intervento di correzione da parte di un utente umano è stato ridotto al minimo. Alcuni OCR riescono addirittura ad ottenere dei buoni risultati anche con testi scritti a mano. A me è capitato di scansionare appunti di lavoro e ritrovarmeli belli belli in word, a discapito della mia scrittura da zampe di gallina.
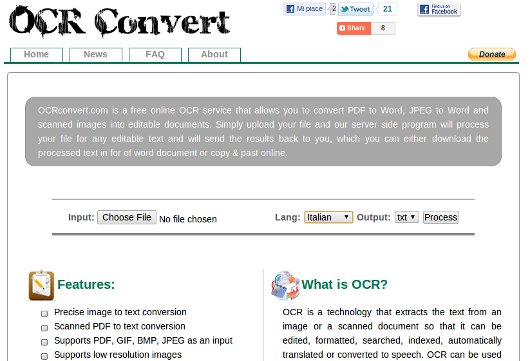
OCRconvert.com è il sito di cui parliamo oggi. Dico subito che si limita al riconoscimento dei caratteri tipografici, quindi non provate a decifrare le ricette del medico: non ci capite niente voi e men che meno il software del sito. Ma per i caratteri tipografici va più che bene.
Il sito, completamente gratuito, permette di caricare documenti PDF, anche multipagina, e immagini in vari formati comuni (jpg, bmp, gif, tiff, png). I linguaggi supportati sono cinque (inglese, spagnolo, francese, tedesco e italiano) e il formato in cui ci viene restituito il testo è il comunissimo e diffusissimo txt, il che vuol dire che il testo non sarà formattato: peccato.
Convertire un testo è abbastanza semplice, una volta caricato il file e scelta la lingua basta cliccare sul pulsante “Process” e attendere: l’elaborazione è molto rapida per le immagini e per i pdf con una o due pagine, ma tende a prolungarsi se l’ocr deve essere applicato a documenti multipagina. Interessante anche la possibilità di processare contemporaneamente fino a cinque documenti distinti: velocizza sicuramente il lavoro.
Il sito è recente, di appena qualche mese fa, ed è completamente gratuito. Le funzionalità sono complete, ma gli stessi autori precisano che è tutt’ora un work in progress: si prevede che in poco tempo il testo scansionato potrà essere scaricato in vari formati, tra cui alcuni che mantengano la formattazione originale. Inoltre, sempre in sede di pianificazione, si sta lavorando per poter estrarre testo da più di cinque documenti alla volta.
2 commenti
che programma o sito hai utilizzato per trasformare in word i tuoi appunti di lavoro, scritti a mano?